[머신러닝] 2. 머신러닝 시스템의 종류 - 2
두비니
·2020. 3. 2. 01:04
이 글은 '핸즈온 머신러닝' 책에
기반하여 작성되었습니다.
2. 머신러닝 시스템의 종류 - 2
머신러닝 시스템의 종류는 크게 세가지 범주로 나누어 생각합니다.
-사람이 지도하는가 (지도학습, 비지도학습, 준지도학습, 강화 학습)
-실시간으로 학습을 하고있는가 (온라인학습, 배치학습)
-실제 사례 기반인지 예측하는것인지 (사례기반학습, 모델기반학습)
오늘은 두번째 범주의 이야기!!
2.2) 배치 학습과 온라인 학습
머신러닝 시스템을 나누는 또다른 기준은 점진적으로 학습하고 있는가입니다.
2.2.1) 배치 학습
배치 학습은 시스템이 점진적으로 학습할 수 없는 경우를 얘기합니다. 점진적으로 학습할 수 없다는 것은, 미리 학습단계에서 습득한 알고리즘을 통해 일련히 적용만 시킨다는 뜻입니다. 이런 학습방법을 오프라인 학습이라고 하구요.
그렇다면 배치학습 시스템이 새롭게 제공되는 데이터들에 대해서도 반응을 하고싶다면?
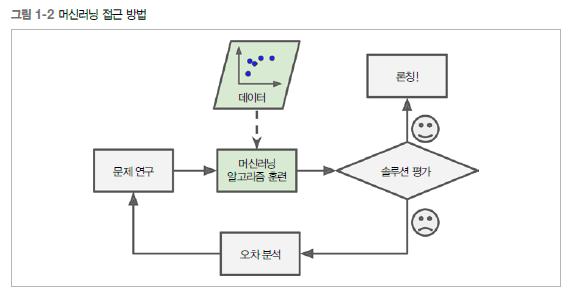
우리가 전글에서 봤었던

이 방법을 새로운 데이터셋과 이전 데이터셋을 모두 합친 새로운 데이터셋을 학습시킨 새로운 버젼을 다시 론칭(업데이트)해야합니다.
그래도 다행인건 위의 모든과정이 쉽게 자동화가 될 수 있다는 점이죠.
따라서 그냥 자주 학습시키면 해결이 되긴 합니다.
이 방식은 간단하고, 문제도 없긴 하지만, 단점이 몇가지 있습니다.
1. 비용이 많이 듭니다. 계속 늘어나는 전체 데이터셋을 가지고 학습을 시키려면, 많은 컴퓨터 자원이 필요할 것입니다.(CPU, 메모리 공간, 디스크 공간, 디스크 IO, 네트워크 IO 등)
2. 보통 큰 용량의 데이터셋을 학습시킬경우 몇시간의 시간이 걸립니다. 보통 24시간마다 또는 1주일마다 시스템을 훈련시키는데, 시스템이 빨리 변하는 데이터에 적응해야한다면(ex.주식) 배치학습은 효율적인 방법이 아닙니다.
3. 자원이 제한된 시스템의 경우(ex. 스마트폰, 화성탐사로봇), 학습해야 할 때 많은 양의 훈련 데이터를 나른다는 것 자체가 비효율적인 선택이겠죠.
2.2.2) 온라인 학습
온라인 학습은 배치학습의 반대로, 점진적으로 계속 학습을 하는 방법입니다.
온라인 학습에서는 보통 데이터를 '미니배치'라는 묶음으로 시스템을 훈련시킵니다. 이 방법은 매 학습단계가 빠르고 비용도 적게 들기때문에 데이터가 도착하는대로 즉시 학습할 수 있습니다.
이런 방법의 장점은:
1. 컴퓨팅 자원이 얼마 들지 않는다.
2. 배치학습과 달리 데이터 샘플을 학습시킨 후에는 버리면 되기때문에 공간절약가능
대신 단점은
1. 구현하기 훨씬 더 까다롭고
2. '나쁜 데이터'에 너무 큰 영향을 받습니다.
나쁜 데이터에 대해서는 아래에서 더 자세히 얘기해보겠습니다.
따라서 이 방법을 응용한 방법도 있습니다.
외부 메모리 학습이라고 하는데, 가진 메모리의 양보다 더 큰 데이터셋을 학습해야할 때, 이 데이터셋을 미니배치로 나눈 후 일부 데이터를 점진적으로 학습시키는 방법입니다.
단, 여기서 주의해야할 점은
이름은 온라인 학습이지만, 온라인에서 진행되지 않는다는 것입니다.
녜??? 뭔 개소리세요라고 할수도 있겠지만
'온라인'이라는 뜻은 따로 업데이트는 할 필요가 없이 사용이 가능하다는 뜻에서 사용됐다고 이해를 하면 될 것 같고,
위에 설명한 과정은 오프라인에서 일어납니다.
이는 솔직히 지금은 이해하기 힘들 수도 있지만, 지금은 그냥 '아 그렇구나'로 남겨두고, 나중에 실습을 해보면 훨씬 더 좋을 것 같습니다.
마지막으로 온라인 학습 시스템에서 중요한 파라미터 하나가 있는데, 이는 학습률입니다.
학습률이란 변화하는 데이터에 따라 얼마나 빠르게 적응하느냐에대한 파라미터입니다.
학습률을 높게하면 시스템이 데이터에 빠르게 적응하지만, 예전 데이터를 금방 잊어버리고 최근 동향만 반영된 알고리즘을 구사할 것입니다.
반대로 학습률이 낮다면 시스템의 관성이 더 커져 느리게 학습하는 대신 예전 데이터는 잘 잊어버리지 않겠죠.
온라인 학습은 참 좋은 방법이지만, 치명적인 단점이 하나 있습니다.
그건 바로 '나쁜 데이터'에 대한 취약점인데요.
우선 나쁜 데이터란 악의적/인위적으로 평균의 경향이 아닌 데이터를 말하는데요.
예를 들어 GDP와 행복지수를 예로 들자면,
GDP와 행복지수는 비례하는 것이 일반적인 경향이지만,
의도적으로 반비례하는 데이터를 시스템에 주입하는경우 이는 '나쁜 데이터'라고 할 수 있겠죠.
물론 위의 경우는 공인된 자료를 쓰는 방법이 있겠지만,
그렇지 않은 경우에는 이게 성능저하로 이어지는 큰 문제가 될 수 있겠죠.
'좋은 데이터'에 대한 이야기는 추후에 이야기해보도록 하겠습니다.
다음글은 머신러닝 시스템 분류의 마지막 글입니다.
거기서 만나요
끝!
'etc > 머신러닝' 카테고리의 다른 글
| [머신러닝] 3. 머신러닝의 주요 도전과제 (0) | 2020.03.05 |
|---|---|
| [머신러닝] 2. 머신러닝 시스템의 종류 - 3 (0) | 2020.03.03 |
| [머신러닝] 2. 머신러닝 시스템의 종류 - 1 (0) | 2020.03.01 |
| [머신러닝] 1. '진짜' 머신러닝을 하기 전 알아야 할 이론적인 이야기 (0) | 2020.02.29 |
| [머신러닝] abstract (0) | 2020.02.29 |





