
[OS] Scheduling Algorithm - 1 (FCFS, SJF)
두비니
·2021. 4. 27. 05:23
Scheduling Algorithm - 1
FCFS, SJF
1. FCFS(First-Come, First-Served) Scheduling
가장 먼저 생각할 수 있는 알고리즘입니다.
따로 생각할 필요 없이, ready queue에 쌓이는 순서대로 바로 CPU에게 연결시켜주는 알고리즘입니다.
그냥 FIFO방식인 queue와 완벽하게 똑같습니다.
예시와 함께 봅시다.

다음과 같이 ready queue가 쌓여있다고 가정합시다. 순서는 P1, P2, P3의 순서로 쌓여있다고 가정합시다. 또한, I/O는 발생하지 않는다고 가정합니다.
그럼 이 ready queue에 대해서 실행시키는 과정을 그림으로 그려봅시다.

다음과 같이 볼 수 있겠죠?
앞서 배웠던 평가 척도를 적용시킵시다.
Waiting time
| P1 = 0 P2 = 24 P3 = 27 average waiting time : (0+24+27)/3 = 17 |
Turnaround time
| P1 = 24 P2 = 27 P3 = 30 average turnaround time : (24+27+30)/3 = 27 |
다음과 같이 구할 수 있습니다.
자 그럼 위 경우와 동일하지만, queue에 쌓여있는 순서가 P2, P3, P1인 경우를 봅시다.
그럼 우선 Gantt Chart는 다음과 같이 그려지겠죠

네 그리고 동일하게 waiting time과 turnaround time을 측정시켜봅시다
Waiting time
| P1 = 6 P2 = 0 P3 = 3 average waiting time : (6+0+3)/3 = 3 |
Turnaround time
| P1 = 30 P2 = 3 P3 = 6 average turnaround time : (30+3+6)/3 = 13 |
네. 구해진 값을 보면 알 수 있듯이 순서만 바꿨는데도 전체적인 효율이 증가한 것을 볼 수 있습니다. 이러한 하나의 큰 프로세스 때문에 다른 프로세스들이 기다려야 하는 현상을 convoy effect라고 합니다.
2. SJF(Shortest Job First) Scheduling
다음은 SJF입니다. 이름에서부터 알 수 있듯이 Shortest Job, 즉 시간이 가장 적게 걸리는 프로세스부터 처리하겠다는 뜻입니다. 위에서 covoy effect로 봤듯이 시간이 짧은 것들을 처리했을 때 효율이 높아지기 때문이겠죠?
그래서 shortest-next-CPU-burst algorithm이라고도 합니다.
예시로 들어가기 전에, SJF scheduling 기법의 경우에는 realworld에서는 사용하기 힘듭니다. 왜냐하면 기본적으로 짧게 걸리는 프로세스를 기준으로 할당하겠다는 소리인데, 사실상 프로세스의 길이를 예측하는 것은 매우 힘든 일이기 때문입니다.
그렇기 때문에 우선 윈도우, 그리고 리눅스에서는 이러한 알고리즘을 사용하고 있지 않습니다. 정말 이론상으로 배우는 것이라고 보면 편할 것 같고, 이렇게 예시로 드는 burst time의 경우에는 예측된 시간이라고 보는게 가장 적절할 것 같습니다.
그럼 예시를 봅시다.

다음과 같이 프로세스들이 queue에 쌓여있다고 가정하면,

다음과 같이 할당되게 됩니다. 가장 burst time이 짧은 것부터 처리함을 알 수 있죠.
그럼 이제 각 척도를 계산해 봅시다.
Waiting time
| P1 = 3 P2 = 16 P3 = 9 P4 = 0 average waiting time : (3+16+9+0)/4 = 7 |
Turnaround time
| 1 = 9 P2 = 24 P3 = 16 P4 = 3 average turnaround time : (9+24+16+3)/4 = 13 |
- 특징
- 평균 대기시간을 최소화함
- CPU 사용시간을 미리 알 방법이 없음.
- 예측을 하거나
- time limit 값을 가지고 계산(ex. alarm걸어놓은 경우)
- Nonpreemptive and Preemptive
SJF 스케줄링은 비선점, 선점 스케줄링을 모두 할 수 있습니다. 각각의 경우는 다음과 같습니다.
Nonpreemptive
현재 진행중인 프로세스는 무조건 끝내고 다음거 시작
예시로 하는게 편해서 이거부터 봅시당


무조건 하나가 시작하면 끝내야하기 때문에 끝나는 시점에서 다시 비교해서 실행시키는 것을 볼 수 있습니다.
Average Waiting Time은 (0+6+3+7)/4 = 4
Preemptive
상황을 봐서 시간이 덜 걸리는 애가 있으면 걔 먼저
+) Shortest Remaining Time First(SRTF)
그리고 preemptive의 경우에 예시를 봅시다.
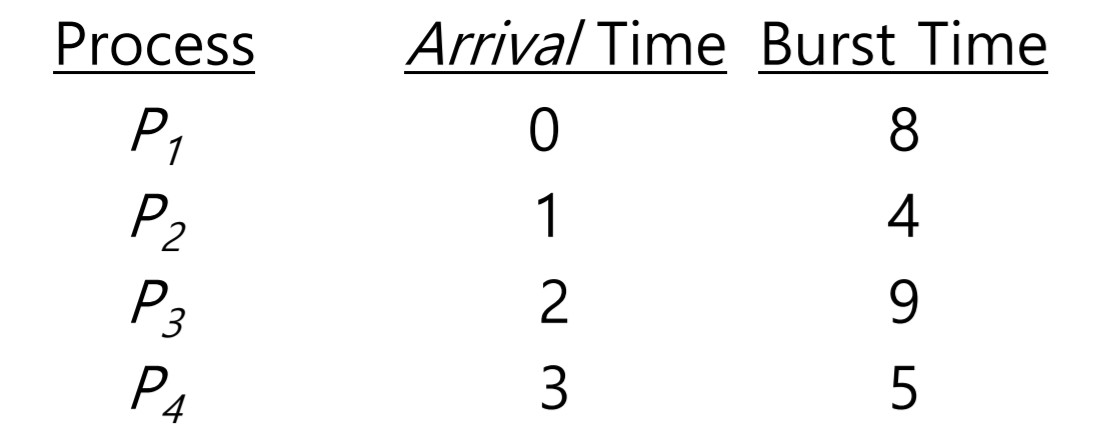
그럼 그래프는 다음과 같이 그려집니다.

1. 0초에 들어온 P1이 실행됨.
2. 1초에 P2가 들어옴. P1(7초) vs. P2(4초) 비교해서 P2실행.
3. 2초에 P3이 들어오지만 P3(9초) vs. P2(3초) 비교해서 P2 계속 지속.
4. 3초에 P4들어옴. P4(5초) vs. P2(2초) 비교해서 P2 지속.
5. 5초에 P2가 끝남. 그다음으로 가장 짧은 P4 실행
6. 10초에 P4 끝. P1 실행
7. 17초에 P1 끝. P3 실행
그럼 Average Waiting Time은 ((10-1)+1+17+5)/4 = 6.5
- CPU Burst 예측하기
일단 CPU burst time을 예측하기 위해서 많이 노력을 했습니다. 일단 할수만 있으면 최고니깐요.
그래서 보통은 지수함수 기반의 값들을 가지고 값을 구합니다.

자 지금 위의 내용들은 Burst Time을 예측하기 위해서 쓰이는 값들입니다.
설명입니다.
- tn은 실제 running상태에서 얼마나 오래 있었는지, 𝜏n+1는 tn을 알 수 없으니 처음 가지고 시작하는 값입니다.
- 그리고 마지막으로 α는 가중치를 말합니다. 타우에 둘 것인지, t에 둘 것인지에 따라서 burst 예측값이 달라지겠죠?
그래서 주어진 식을 주우우우욱 대입시킨다면
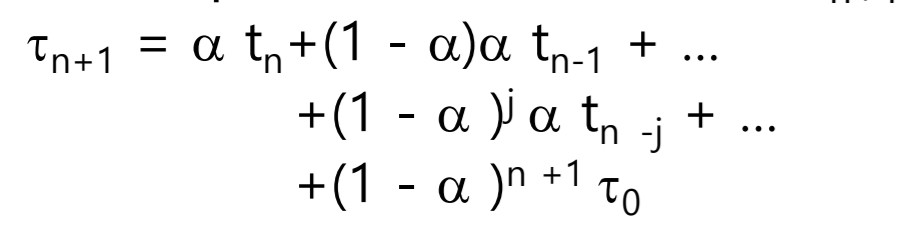
이런 식이 나오는데, 외우기보다는 의미만 보면 될 것 같습니다.
알파값은 0에서 1 사이이기 때문에, 더 예전 값으로 갈수록 가중치는 적어진다고 볼 수 있겠습니다.

마지막으로 그래프만 하나 더 볼건데, 식을 실제로 계산한 값이라고 볼 수 있습니다. 타우가 계산값이고, t가 실제 값인데, 정확하지는 않지만 전체적인 경향을 따라간다는 것을 보면 될 것 같습니다.
'Coding_Algorithm > Operating System' 카테고리의 다른 글
| [OS] Scheduling Techniques Depending on Environment (0) | 2021.04.28 |
|---|---|
| [OS] Scheduling Algorithm - 2 (RR, Priority Scheduling, Multilevel Queue) (0) | 2021.04.27 |
| [OS] Scheduling 알고리즘 평가 척도 (0) | 2021.04.26 |
| [OS] Nonpreemptive Scheduling vs. Preemptive Scheduling (0) | 2021.04.25 |
| [Kernel] System Call에 대하여 (0) | 2021.04.02 |




