[머신러닝] 앙상블 모델에 대하여 - Bagging, Boosting
두비니
·2020. 8. 10. 14:19
오늘은 앙상블 모델에 대해서 이야기해봅시다.
우선 "앙상블"이라는 단어 자체를 한 번 봅시다.
앙상블(Ensemble)이란 조화, 통일을 뜻합니다. 머신러닝에서의 앙상블 모델도 "여러 모델이 동일한 문제를 해결하고 더 나은 결과를 얻도록 훈련시키는 기계 학습 패러다임"을 기반으로 만들어진 모델입니다.
보통 하나의 모델로 원하는 성능을 낼 수 없을 때 앙상블 학습을 사용하며, 개별로 학습한 여러 모델을 조합하여 일반화할 경우 성능을 향상시킬 수 있다는 것이 앙상블 모델이 주장하는 바입니다. 개인적으로 공부해본 결과 "집단지성"이라는 단어가 가장 어울리는 모델이라고 생각합니다.

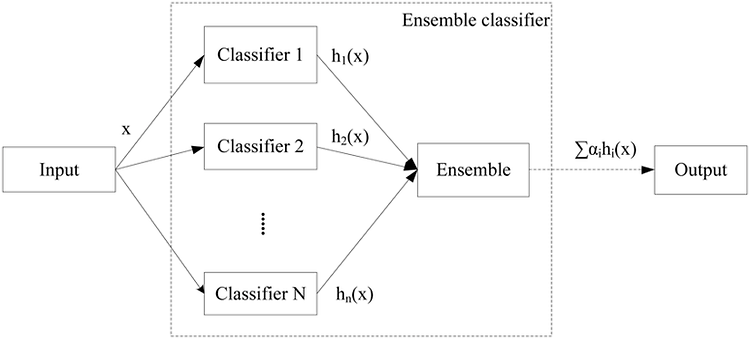
다음은 앙상블 모델을 사용한 Classifier의 예시입니다. 앙상블 모델을 사용할 경우
1. 과적합(overfitting) 감소 효과가 있음
2. 개별 모델 성능이 잘 안 나올 때 앙상블 학습을 이용하면 성능이 향상될 수 있음
대표적으로 두 가지 정도의 장점이 있습니다.
이러한 앙상블 학습법에는 대표적으로 배깅(Bagging)과 부스팅(Boosting)이 있고, 각각에 대해 설명해 보도록 하겠습니다.
배깅 (Bagging)
Bagging은 Bootstrap Aggregation의 약자입니다. 우선 Bootstrapping에 대해서 정의해봅시다.

일단 웹사이트 디자인할때 쓰는 친구 아닙니다ㅎ. 우선 머신러닝에서 거론되는 Bootstrapping이란 통계학에서 사용되는 단어로, 가설 검증을 하기 전에 복원 추출을 적용하여 train set을 만든다고 생각하면 편할 것 같네요.
참고로 비복원 추출, 즉 중복을 허용하지 않고 데이터셋을 나누는 것은 페이스팅(Pasting)이라고 하네요. 알아두면 좋을 것 같습니다.
아무튼 Bagging은 다음과 같이 Bootstrapping된 샘플들을 가지고 각각 모델에게 학습시킵니다.(각자 다른 샘플을 다른 모델에 넣음) 그 후, 학습된 모델의 결과를 집계하여 최종 결과 값을 구합니다. 기본적으로 부트 스트랩 샘플은 대략 독립적이며 동일하게 분포되어 있으므로(i.i.d) 이 과정을 통해 분산이 적은 모델을 얻을 수 있게 됩니다.
이런 방식으로 각각의 결과값에 대하여 이산적인 데이터(Categorical Data)는 투표 방식(Voting; 다수결이라고 생각하면 편할 것 같아요)으로 결과를 집계하며, 연속적인 데이터(Continuous Data)에 대해서는 평균으로 집계합니다.
추가로, bootstrapping의 결과를 단일 모델만 이용해서 사용하는 경우입니다. 이 경우는 단일 모델의 성능을 높이기 위한 경우겠죠. 모델의 정확도를 높이기 위해서는 같은 데이터를 반복해서 학습시키는 것이 중요한데, 이 방식으로 반복학습하는 것은 특히 구분이 잘 되는 샘플에 대해 여러번 학습시키므로 비효율적이다. 따라서 bootstrapping을 진행할 때, 어려운 샘플(이전 분류에서 틀린 분류를 했던 샘플)이 선택될 확률을 증가시켜서 데이터셋을 구성합니다. 이후 학습하는 것을 반복합니다.
사실 이게 boosting이랑 방법이 거의 같다고 생각하지만, 둘다 같은 앙상블 모델이니 어쩔 수 없이 비슷한 부분이 있다고 생각합니다.

예를 들어봅시다. 위 사진에서 회색으로 표시된 선은 단일 모델에 대한 결과값들입니다. 각 회색선들로 표시된 각각의 model들은 overfitting되어있지만, 그의 평균인 빨간 선은 비교적 안정적인 걸 볼 수 있습니다.
부스팅(Boosting)
다음은 부스팅입니다. 배깅(Bagging)이 분산을 최소화하는 것을 목표로 하였다면, 부스팅(Boosting)은 아무튼 성능 자체를 강화하는데 목적을 둡니다. 즉 편향(bias)가 높은 경우 이를 낮추기 위해서 많이 사용합니다.
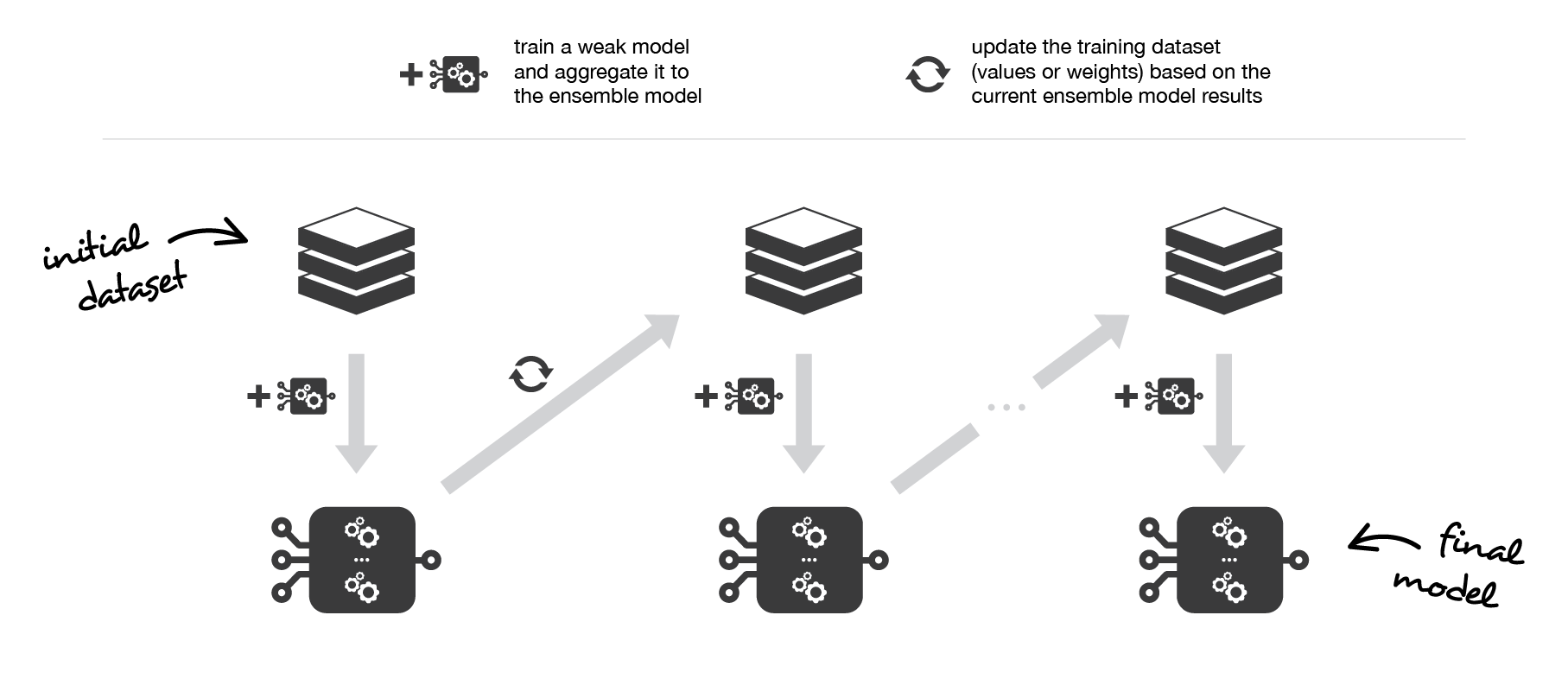
첫 번째 데이터셋의 결과가 다음 데이터셋에 영향을 주는거 보이시죠? 이런 식으로 부스팅은 약한 학습자(weak classifier)에게 적합하게 반복하여 앙상블 모델에 집계하고 다음 기본 모델을 피팅할 때 현재 앙상블 모델의 강점과 약점을 더 잘 교려하도록 훈련 데이터 세트를 "업데이트"하는 것으로 구성됩니다.
이 부스팅 방법에도 크게 Adaboost과 Gradient Boosting으로 나뉩니다. 두 방법 모두 bias를 낮추기 위해 사용되지만, 이 순차적으로 진행하는 동안 학습자를 생성하고 집계하는 방식이 다릅니다. 이 내용을 중심으로 각각 설명하도록 하겠습니다.
AdaBoost; Adaptive Boosting
이름에서도 볼 수 있듯이 적응형 부스팅이라고 합니다. 여러가지 수식들이 있는데 이건 우리 머리를 위해서 스킵하도록 합시다.
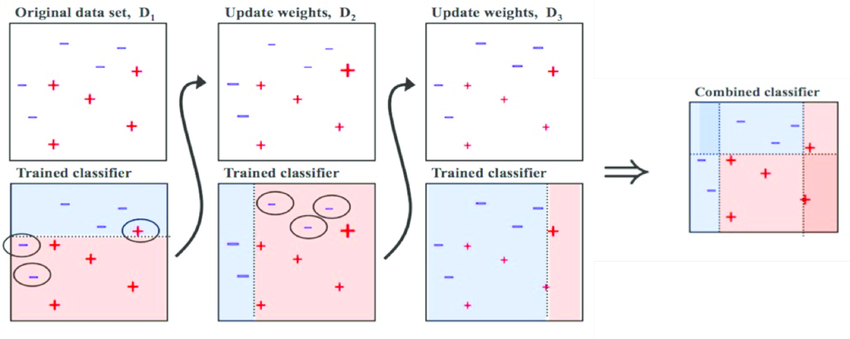
위 사진을 보면 첫 번째 데이터셋만 Original data set이라고 표기되어있고, 그 다음부터는 Update weights라고 되어있는게 보이나요?
AdaBoost는 각 반복에서 관측치의 가중치를 업데이트합니다. 첫 번째 결과에서는 세 개의 관측치가 잘못 분류되었죠?
그럼 이 세 개의 관측치에 대해 가중치를 증가시킵니다. 그 상태로 분류를 하니 새롭게 잘못 분류된 관측치가 3개가 발견되었네요. 그러면 기존의 가중치를 증가시켰던 관측값에 대해서는 가중치를 줄이고, 새롭게 생긴 오답 관측치에 대해서 가중치를 증가시킵니다. 그런식으로 반복한 뒤 이를 합친게 최종 결과라고 볼 수 있겠죠?
Gradient Boosting
그래이디언트 부스팅은 이전 약한 분류기에서 발생된 잔차에 대해 다음의 약한 분류기를 적합시키는 것이 특징입니다. Gradient Boosting과 Adaboost의 가장 큰 차이점은, Gradient는 일단 하나의 초기 예측값으로 시작한다는 것입니다. 이 값을 바탕으로 새로운 classifier를 만들어 나가는 것이죠. 많은 글들에서 이 분류기를 tree라고 소개합니다. 딱히 tree말고는 방법이 없는거 같기도 하구요.

결론적으로 하나의 예측 결과값(보통 평균)을 통해서 틀린 값이 있다면 그것에 대해서 새로운 판단 방법을 만들어 나가는 방법이다. Adaboost가 데이터셋을 업데이트 해나간다면 Gradient Boost는 분류기 자체를 업데이트해가는 느낌으로 보면 될 것 같네요.
너무 간략하게 써서 잘 설명한 영상 첨부합니다 : https://www.youtube.com/watch?v=3CC4N4z3GJc
이것의 대표적인 예시가 요즘 핫한 XGBoost, LightGBM이 있습니다.
배깅과 부스팅의 차이

Bagging과 Boosting의 결론적인 차이는 Bagging은 병렬적으로 처리될 수 있는 반면, Boosting은 순차적으로 학습을 합니다. 한 번 학습이 끝난 후 결과에 따라 가중치를 부여하기 때문에 Boosting이 Bagging보다 훨씬 더 많은 시간이 걸리지만, 오답에 더 집중할 수 있기 때문에 높은 정확도를 가집니다. 또한 어떻게든 맞는 결과값을 내기때문에 Overfitting의 가능성도 Bagging보다 높습니다.
따라서 천편일률적으로 둘 중 하나가 더 좋다고 판단하는 것 보다는 상황에 따라서 알맞는 방법을 선택하는게 좋을 것 같습니다. overfitting이 문제일때는 Bagging을 선택하고, 정확도가 문제라면 Boosting을 사용하는게 좋겠죠?
::참고::
Bootstrap : https://bkshin.tistory.com/entry/DATA-12?category=1042793
why Bootstrap works : https://stats.stackexchange.com/questions/26088/explaining-to-laypeople-why-bootstrapping-works
Wiki/Bagging : https://en.wikipedia.org/wiki/Bootstrap_aggregating
이글 진짜 좋은 듯 : https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
'etc > 머신러닝' 카테고리의 다른 글
| [KDD 2020] An Embarrassingly Simple Approach for trojan attack in Deep Neural Networks 분석 (0) | 2020.08.29 |
|---|---|
| [머신러닝] 3. 머신러닝의 주요 도전과제 (0) | 2020.03.05 |
| [머신러닝] 2. 머신러닝 시스템의 종류 - 3 (0) | 2020.03.03 |
| [머신러닝] 2. 머신러닝 시스템의 종류 - 2 (0) | 2020.03.02 |
| [머신러닝] 2. 머신러닝 시스템의 종류 - 1 (0) | 2020.03.01 |





